

Migrating Jira from one cloud instance to another can be a complex endeavor, involving several critical steps to ensure data integrity and minimize disruption. Customers may occasionally want to consolidate multiple Jira cloud accounts into a single account or switch to a different Jira cloud account. In these cases, they can leverage the Jira cloud-to-cloud migration process.
When migrating Jira data between cloud instances, a project-level export can be a practical solution, especially if there is a need to transfer specific projects rather than the entire instance. Atlassian offers specialized tools designed to simplify and automate the cloud-to-cloud migration process.
In essence, transferring data from a source cloud instance to a target cloud instance can be broken down into three main steps:
- Exporting data from the source cloud instance
- Applying transformations such as filtering and merging
- Importing it into the target cloud instance

This blog post takes a deep dive into the Jira Cloud Data Export Service, highlighting its evolved architecture designed to boost throughput while working within the constraints imposed by the overall Jira architecture. The Jira Cloud Data Export Service is a platform service that facilitates the export of data from the source Jira cloud instance at the project level.
What is Jira Cloud Data Export Service?
Jira Cloud Data Export Service empowers customers to extract data from their Jira cloud instance for various purposes including backup, analysis, and migration. This service enables project-level exports and accommodates over 100 logical entity types linked to a project. An exported project includes its issues, configurations, users, and group references, ensuring a comprehensive dataset.
The Jira Cloud Data Export Service, as illustrated below, processes project-specific export requests from the Cloud Migration Assistant. It extracts the relevant project data from Jira Cloud and stores this information in the data store, specifically DynamoDB. Once the extraction of all project-related data is finalized, the service uploads the data to an S3 bucket in a portable format.
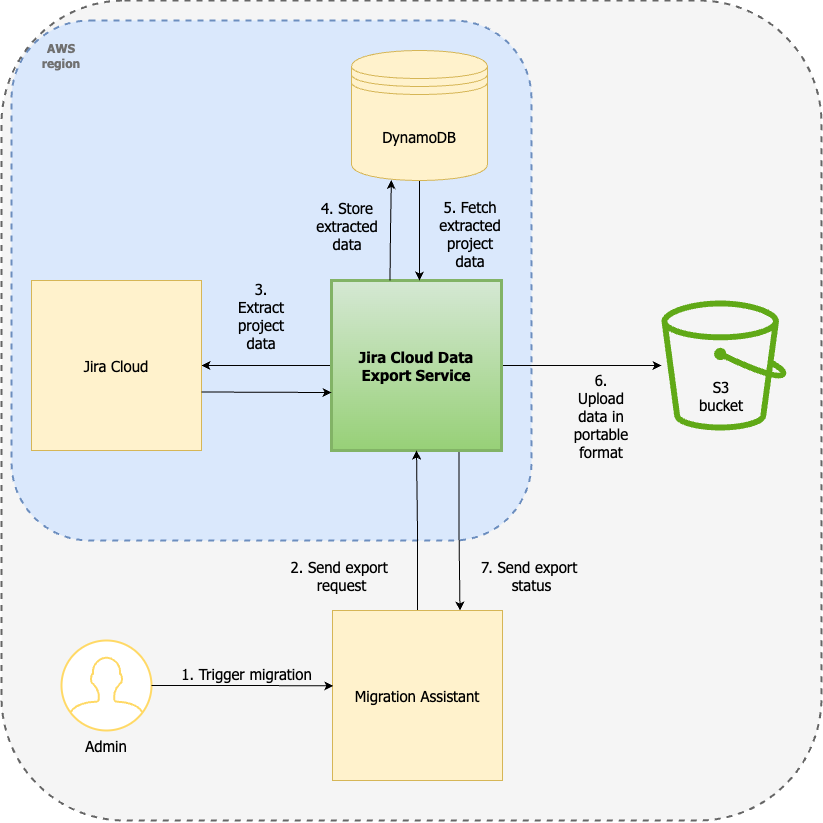
Understanding Jira data constraints in the context of Jira data export
Let’s first understand the constraints of exporting data from the Jira cloud instance.
The Jira data model is the underlying structure that defines how data is organized, stored, and managed within Jira. A Jira cloud instance can have multiple projects, each with its own set of configurations and data. Jira also allows extensive customization, enabling users to create custom workflows, issue types, and fields. While this flexibility is powerful, it adds complexity because they need to be mapped correctly during migrations. Moving large volumes of data, including issues, comments, attachments, and history, can complicate data management and migration processes. Handling large datasets during export requires extra consideration for data integrity and performance.
Over the months, the Jira Cloud Data Export Service has significantly evolved to improve export throughput while effectively addressing Jira data constraints. This involves maintaining accurate relationships among interconnected entities within the exported project and ensuring that the scope aligns appropriately with the project being exported.
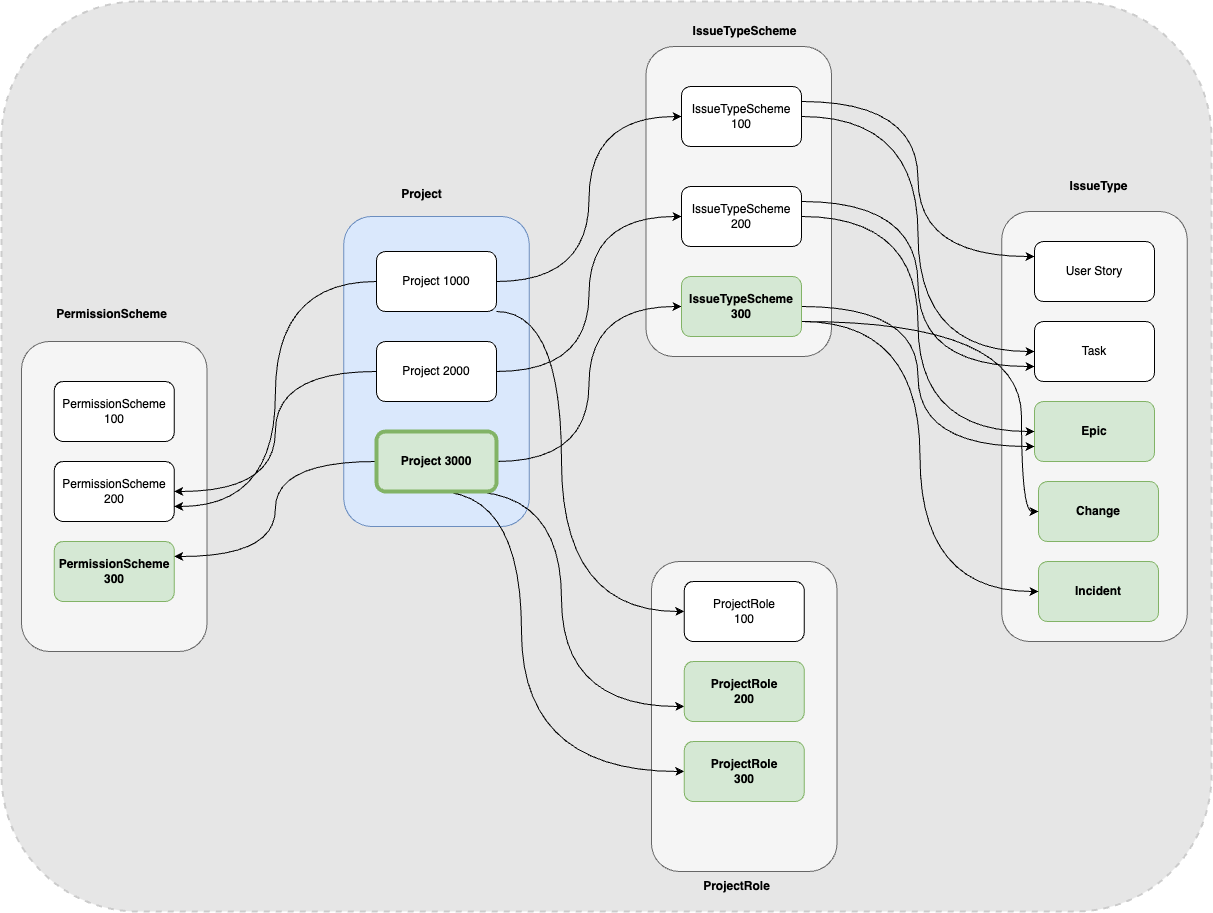
In this section, I will explain what it means to extract Jira data at the project level. A project consists of data, configurations, users, groups, and other entities. Scoped entity export refers to the process of selecting data specific to the chosen project and exporting only associated data.
For example, let’s consider the extraction of Project 3000. In this instance, I have shown five key entities: PermissionScheme, IssueTypeScheme, IssueType, ProjectRole, and Project. As illustrated in the accompanying diagram, to extract Project 3000 in a scoped manner, we need to focus exclusively on the entities highlighted in green, ensuring that only these are extracted.
It is crucial to maintain these relationships (Jira data constraints); otherwise, the exported project data will be corrupted. Imagine attempting to extract project-specific data across more than 100 entity types while still preserving these intricate associations.
When all entity types in Jira and their relationships are modeled as a Directed Acyclic Graph (DAG), traversing the DAG is often one of the efficient ways to extract data in a scoped manner. This presents a fundamental challenge that the export design must overcome. The extraction process starts by retrieving the project entity and then collecting all associated issues linked to that project. This method effectively navigates through the Directed Acyclic Graph (DAG) to fetch all relevant entities needed for a project.

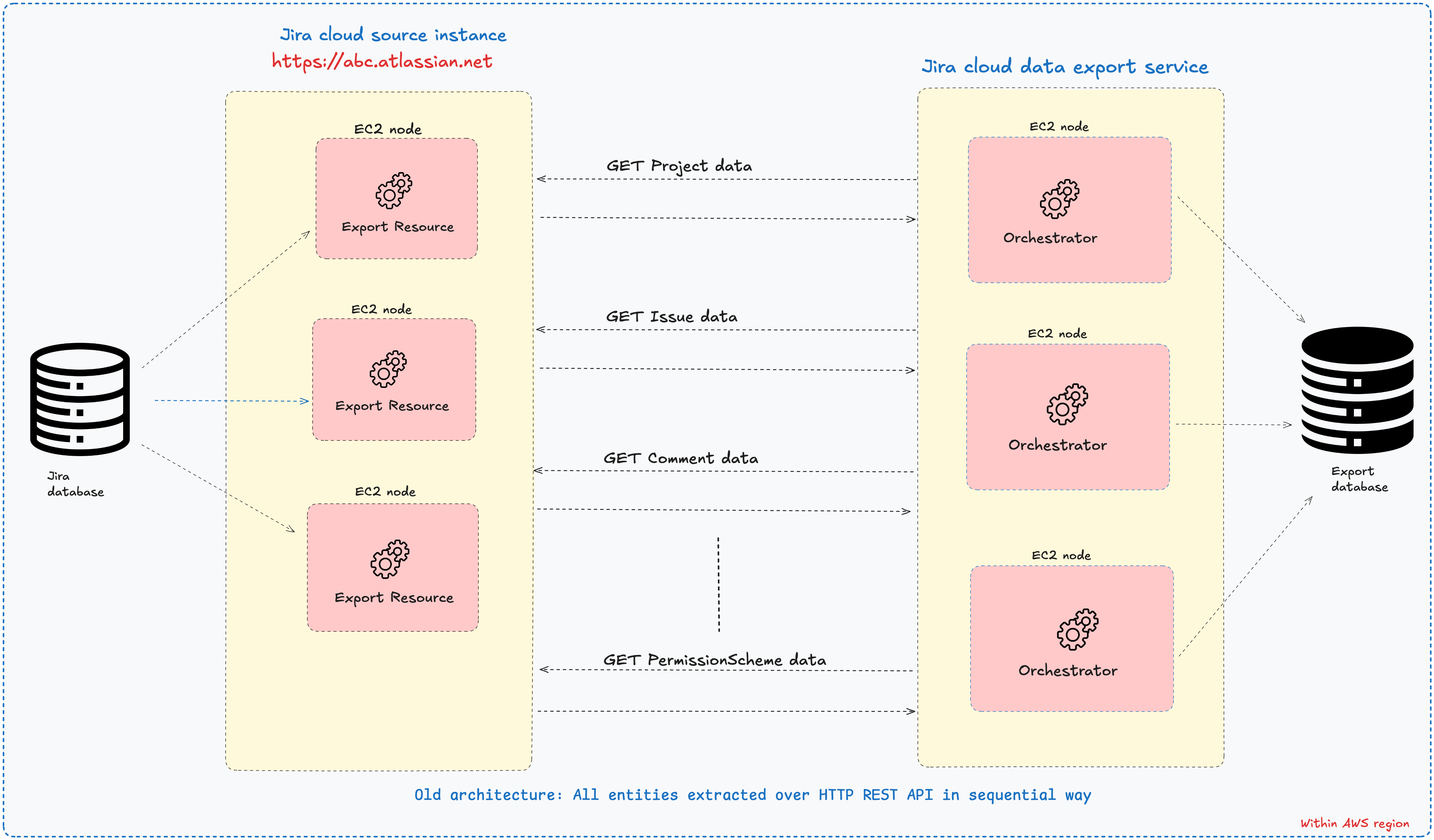
How has the service extracted project data in the past?
In the past, the service had a configured workflow to navigate the entity relationship to extract entities one after another. See the below diagram of the old architecture. As shown, we first extracted the project entity, followed by its children (Issue, Comment, Worklog), and so on in that order. The service always extracted one entity’s data at a time in a paginated way and then moved on to extract the next entity in the sequence and so on till we extracted all the 100+ entities supported. The overall approach was sub-optimal. For instance, even though we knew that all the children of a given parent entity could be extracted in parallel, the architecture was able to support children extraction in sequence because of its inherent limitations. As a result, despite the availability of multiple compute instances within the given Jira cloud environment, the service has architectural limitations in exploiting all the available compute and database resources resulting in diminished export throughput for high-volume entities such as Issue, Change History, and Comment to name a few. Consequently, the time needed to complete the whole project-related data export operation was significantly longer, often exceeding 24 hours.
What did we learn from performance metrics?
The accompanying pie chart clearly illustrates that the top five high-volume entities—namely Issue, Issue History, Comment, and Custom Field—accounted for over 76% of the total project export time. This insight significantly influenced the strategy for evolving the service architecture and its overall data extraction performance.
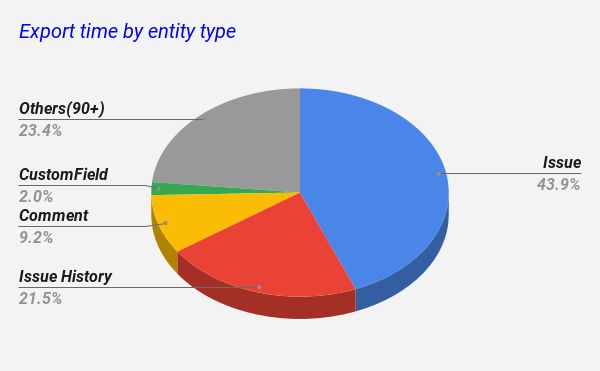
This is a classic example of the Pareto principle and the insight led to two key decisions.
What are those key decisions?
- Architecture changes: We adopted a hybrid approach to evolving the architecture to optimize for the overall export performance. It meant moving all high-volume entities via streaming infrastructure by leveraging Atlassian’s robust streaming platform, Lithium. And, continue to extract all low-volume entities that are intricately complex and interconnected using HTTP Batch APIs in the same old way.
- Code optimizations: To enhance performance and enable efficient data retrieval, it was crucial to identify and fix N+1 queries in key high-volume entity export code paths, in addition to implementing other code optimizations.
New architecture
The service adopted a hybrid approach to optimize for overall export throughput. As shown below, in this approach, high-volume entities were extracted and sent over the streaming platform where Jira Cloud acted as Source processor(extracting entities from Jira data store) and Jira Cloud Data Export Service acted as Sink processor (consuming extracted entities and storing them in the service data store (DynamoDB). The entities extracted either via streaming or via HTTP batch APIs were all written to the service data store. Once the extraction of all the project-scoped entities was done, the Jira cloud data export service would upload the data to S3 in a portable format(JSON).
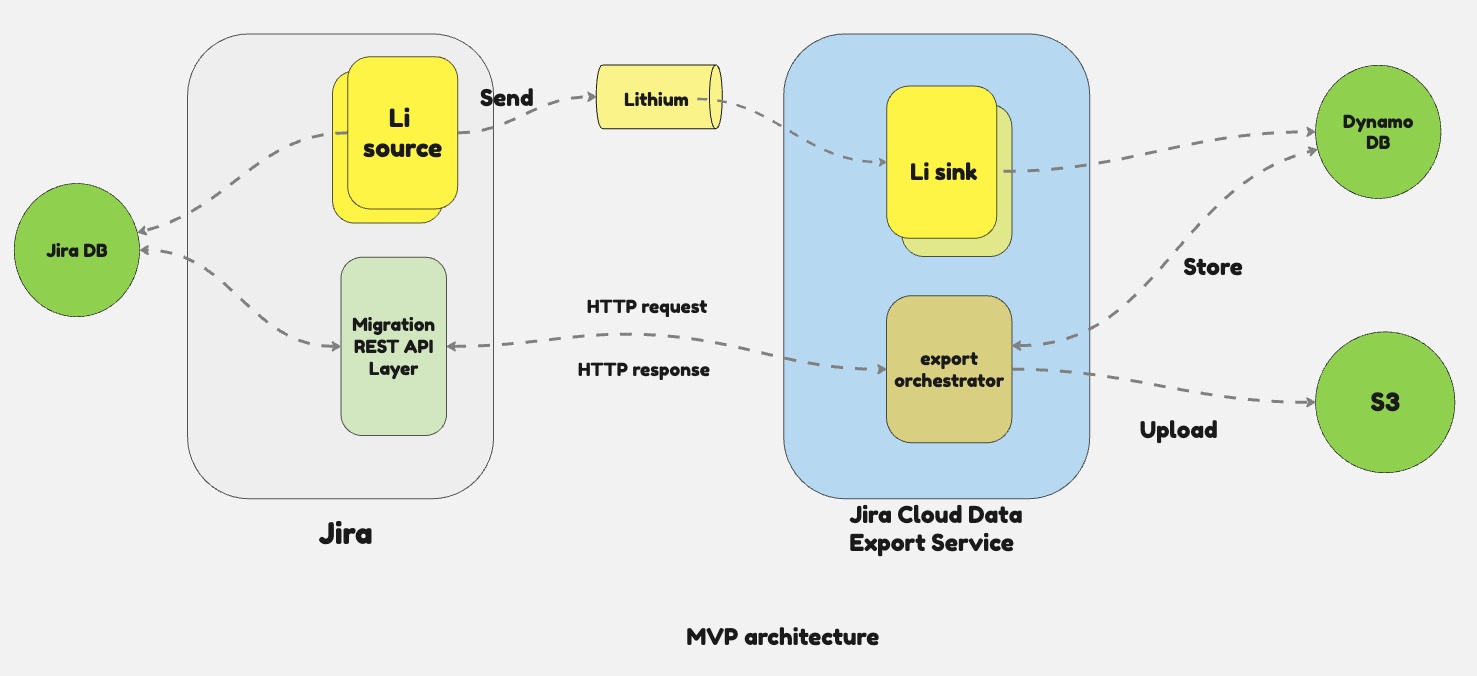
The export streaming design for the extraction of high-volume entities went through multiple phases of evolution. The initial phase was called multi-threaded single-source architecture. As shown below, all the high-volume entities were extracted via a single Jira Cloud Migration Compute Node and had multiple threads running inside the Jira Cloud Migration Node to extract data in parallel and write to Lithium streaming platform. The multiple Jira Cloud Data Export Service compute(EC2) nodes acted as sink processors to consume and transform the extracted entities in parallel and write entities to the data store.

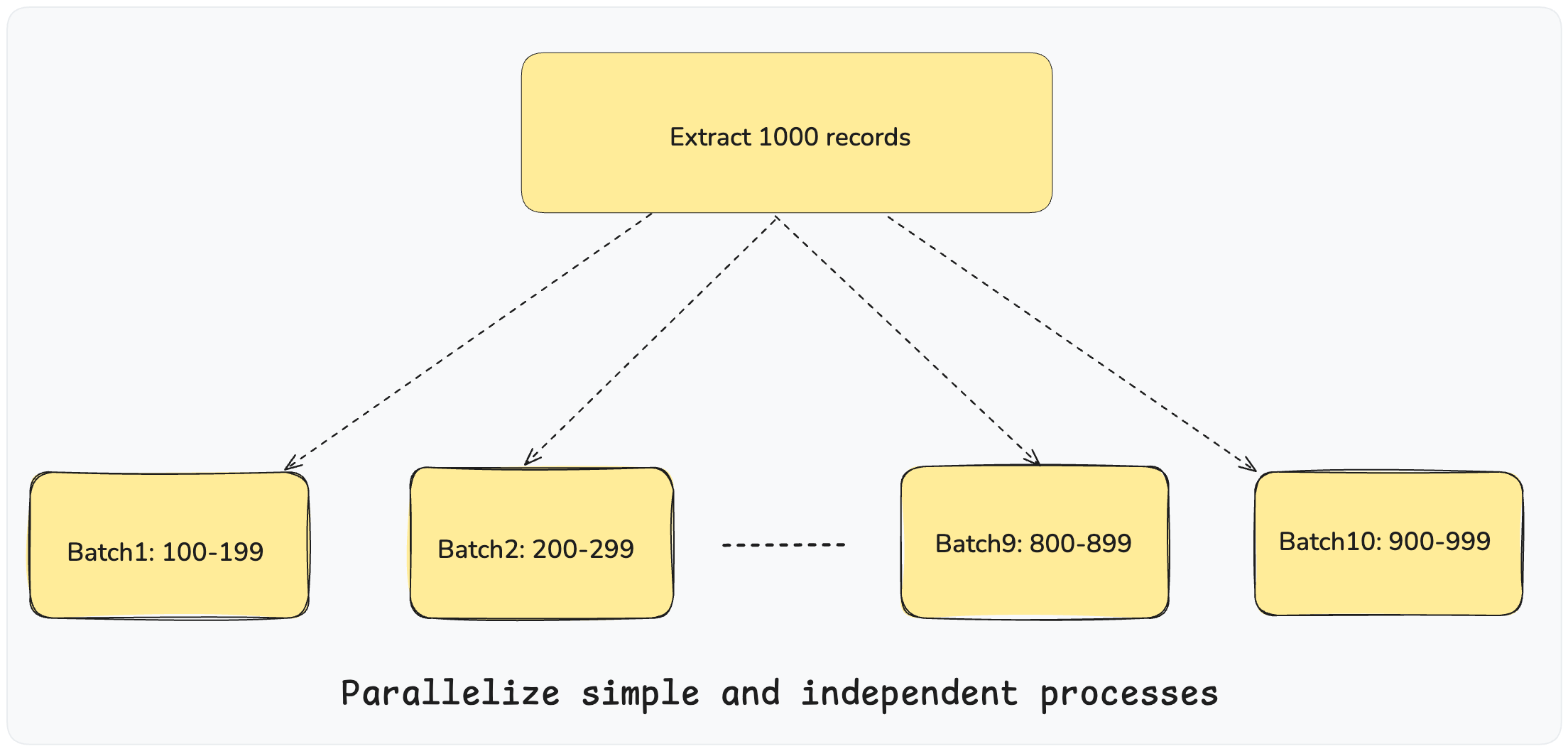
At the core of the design, we optimized high-volume entity extraction by splitting up the whole task into multiple small export jobs and letting multiple threads execute jobs in parallel to enhance the overall extraction efficiency. As shown in the below diagram, let’s say we need to extract 1000 Jira issues from the Jira data store. The process would split the 1000 entity IDs into batches of 100 resulting in generating 10 export jobs and letting those export jobs be executed in parallel by a preconfigured number of threads per single migration compute node. As shown in the above diagram, each Lithium export source processor can run multiple export jobs in parallel and push extracted entities to Lithium.
Evolution of export streaming design for high-volume entities
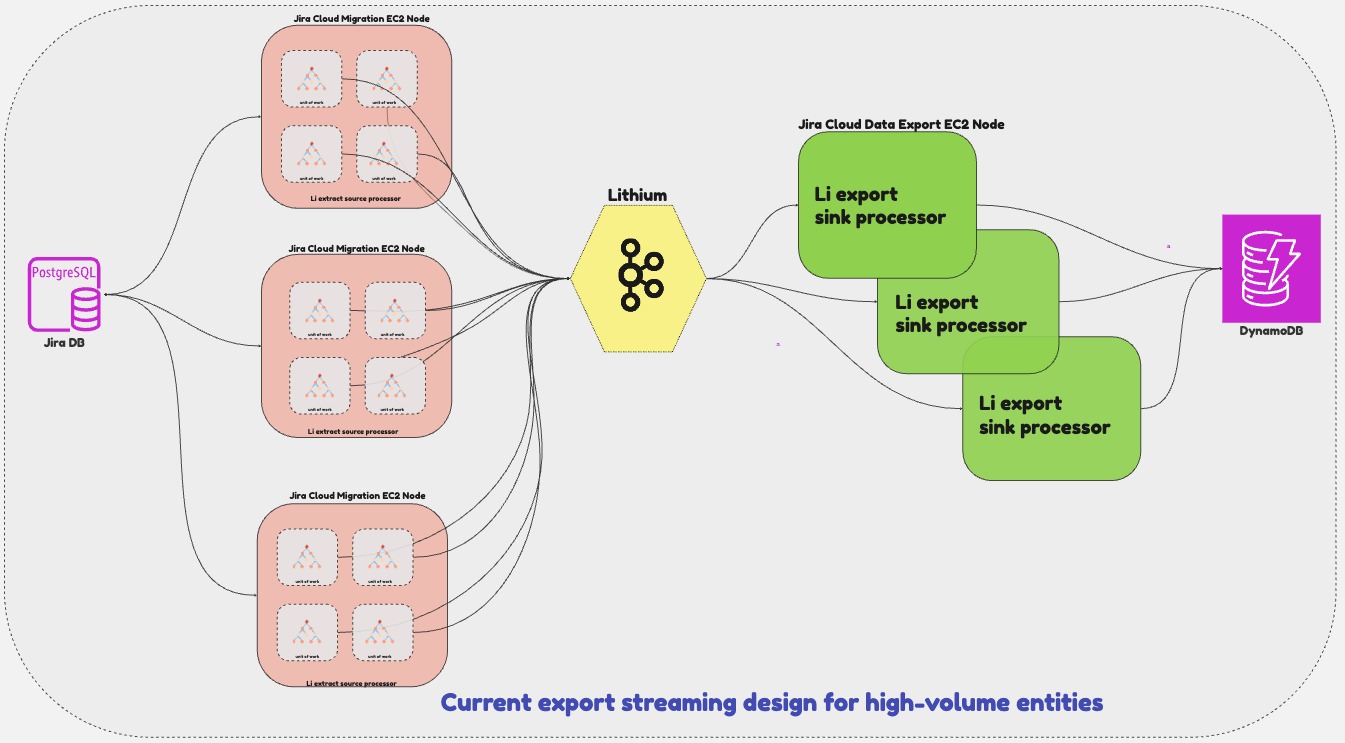
The MVP design to support extraction of high-volume entities over streaming was a really big win as we were able to improve the throughput by 5x against the baseline performance(Refer to the diagram at the bottom that shows the export throughput improvement journey). But, we knew that to unlock the true power of the streaming design, we had to evolve it from multi-thread single-source node to multi-thread multi-node so that we could horizontally scale the source (Jira Cloud Migration Compute instance) nodes and engage the available compute nodes based on the size of the project data. As shown below, in the current export streaming design for high-volume entities, we engage as many available compute nodes as necessary based on the project data size.
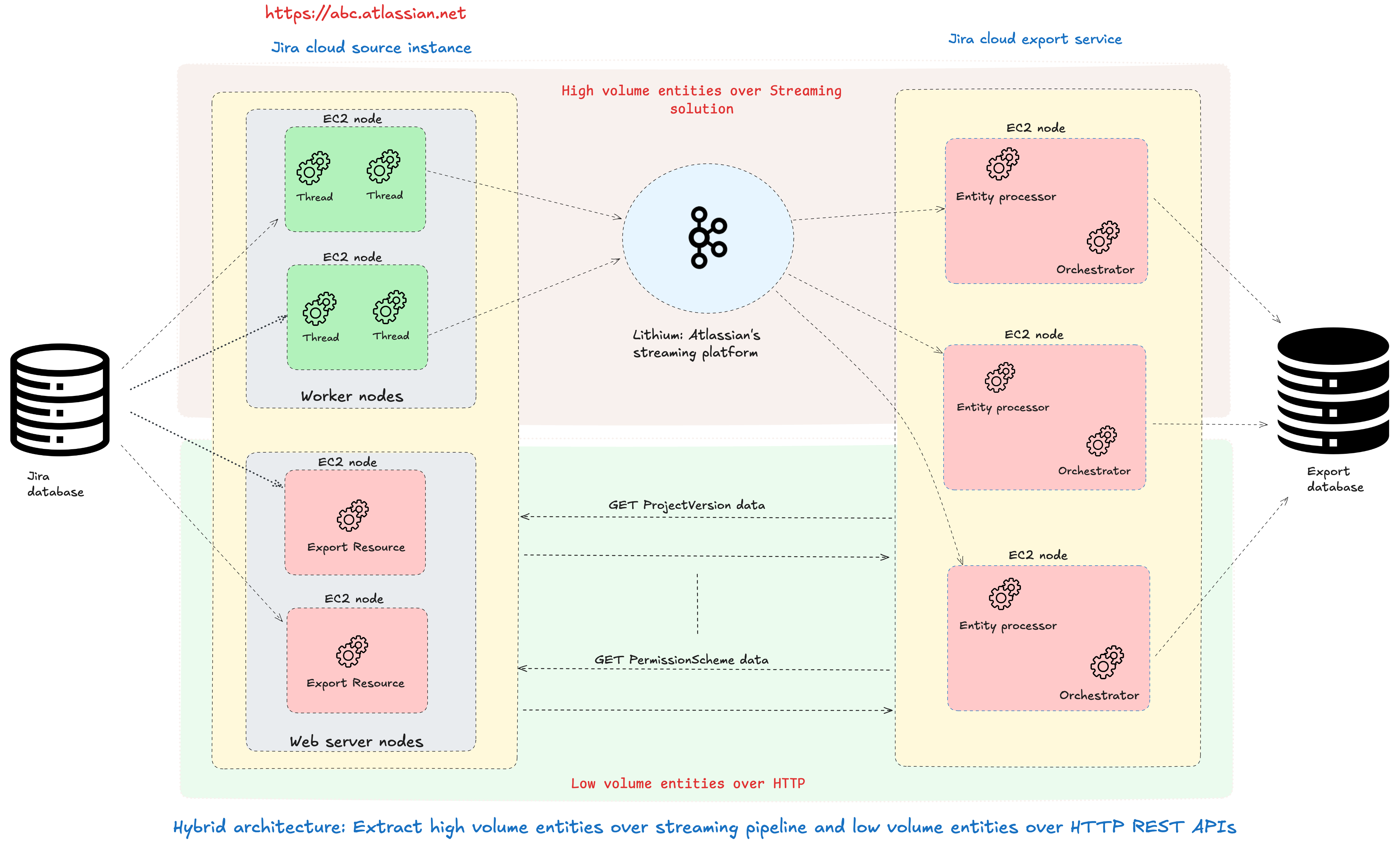
The current state of the hybrid approach
As shown below, high-volume entities are extracted over Lithium, and low-volume entities—often defined by their complexity and interconnections are continued to be extracted using HTTP batch APIs. The low-volume entities are highly interconnected and onboarding them to streaming is a lengthy, complex, and long-tail work in nature. For instance, more than 80% of the project-scoped entities are low-volume in nature. We do not foresee real benefits of extracting these over streaming unless we pivot to other tangible advantages such as moving away from hybrid architecture can lead to simplified overall export design and improved dev productivity.
Code optimisations
Historically, entity APIs were developed with an emphasis on providing intuitive and user-friendly interactions for end-users. As a result, these APIs were not originally designed for extracting large datasets. To address these limitations, the engineering team focused on optimizing the underlying database queries among other code optimizations. This effort resulted in significant enhancements in both the responsiveness and efficiency of the APIs. These improvements are particularly important for managing large datasets, as they ensure that migration can effectively move large entity data.
In the below table, I have included some of the major code optimizations.

Let’s deep dive into one of the N+1 code optimizations we fixed in the IssueLink entity in Jira. An IssueLink serves as a connection between two issues. During the extraction of IssueLink data for a specific project, we identified instances where one of the linked issues does not belong to the project being migrated. This situation poses a risk of potential data loss and must be communicated to the customer through the post-migration report. Previously, to pinpoint such cross-project linked data, we were making two distinct database calls per IssueLink entity and this process was repeated for each IssueLink data requested (typically in batches of 100) in a batch call.
Total db calls = (up to 100 IssueLinks per export batch call) * (2 DB calls per IssueLink)
Most of the time, we would find ourselves making up to 200 database calls just to figure out cross-project linked data. It was a problem that needed our attention. As shown in the above table, the code optimization resulted in an 8x improvement on the 90th percentile (P90).
Code optimization applied: Replace individual getIssueObject() database calls with a single bulk database call getIssueObjectsById(). The below code snipped shows code – before and after applying the code optimization.

Final thoughts
Architectural changes and code optimizations played a crucial role in significantly improving the overall export throughput. The diagram below illustrates their key contributions expressed in export throughput multiplier terms over the last 12+ months. We have scaled the export throughput by 25x compared to the old architecture.
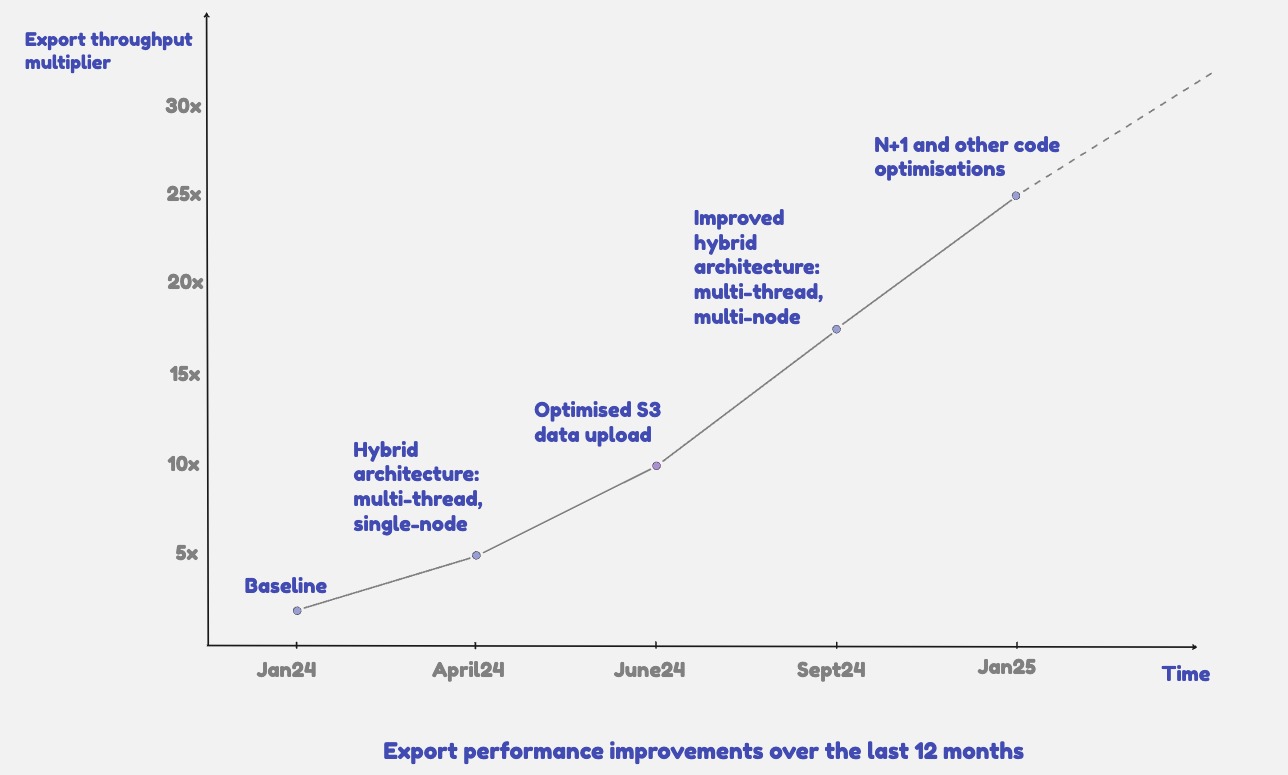
Improving the throughput of Jira data exports has significantly improved the efficiency and reliability of cloud migrations for our valued customers. Most customer exports are now completed in less than 24 hours, regardless of the number of projects included in a migration plan. This positive change has not only minimized overall downtime but has also strengthened customer trust and satisfaction with the overall Jira cloud data migration process.